Overview
An AI-assisted word-by-word translation pipeline that has processed 30,286+ verses across 66 Biblical books (Hebrew Old Testament and Greek New Testament) with full morphological analysis. The system has processed 444,785+ individual words with morphological tagging, etymology, Strong's concordance cross-references, and interlinear formatting.
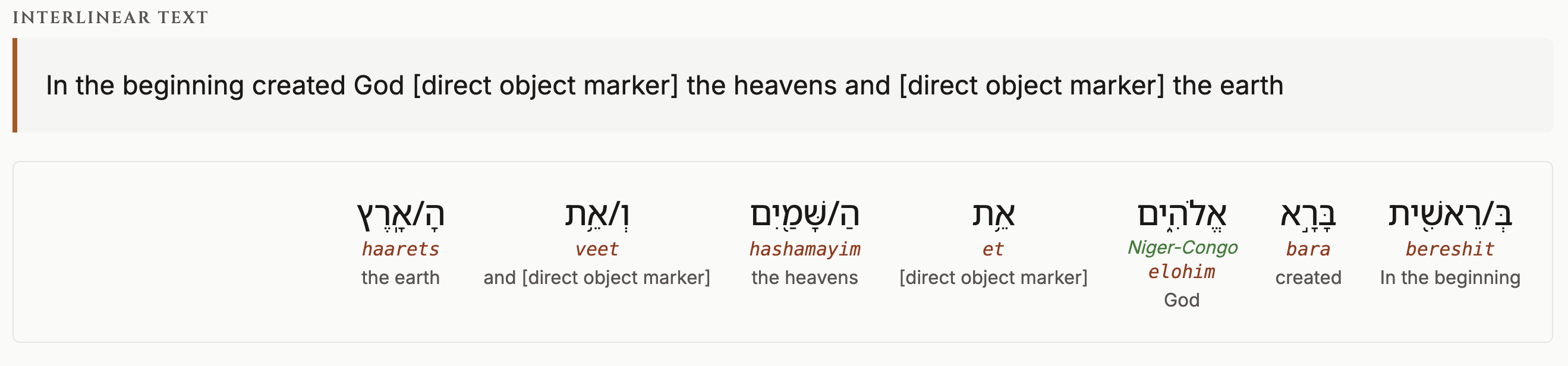
Beyond translation, the project built a structured lexicon database with 475K+ SEO-friendly pages and etymological comparisons across 15 Niger-Congo Bantu languages. The interlinear layout presents each verse with the original language text, transliteration, morphological tags, and English gloss side by side.
Key Features
- 30,286+ verses processed across 66 books (Hebrew OT + Greek NT)
- 444,785+ words with morphological tagging and etymology
- Strong's concordance cross-references for every word
- Interlinear layout: original text, transliteration, morphology, and English gloss
- 475K+ SEO-friendly lexicon pages
- Etymological comparisons across 15 Niger-Congo Bantu languages
Architecture
Source Text (Hebrew/Greek) → Tokenization → Morphological Analysis → Database
↓
Perplexity API
(Etymology, Bantu comparisons)
Database → Interlinear Renderer → Verse Pages (30K+)
↓
Lexicon Builder → SEO Pages (475K+)
↓
Strong's Cross-Reference → Concordance Links
Source texts in Hebrew and Greek are tokenized into individual words, each receiving morphological analysis (part of speech, tense, person, number, case). The Perplexity API provides etymological data and Bantu language comparisons. All data flows into PostgreSQL, which powers the interlinear verse renderer (presenting original text alongside translations) and the lexicon page builder (generating SEO-optimized dictionary entries with Strong's concordance links).
Screenshots
Interlinear Translation Layout
Tech Stack
I build and deploy production AI systems.
Let's talk about your next project.